I didn’t invent statistics nor did I invent machine learning. I’m not a published expert in either field. However, I was on Jeopardy, so that’s got to give me some street cred to be able to talk about the two techniques. The discussion usually boils down to this — regression is a more “pure” form of data analysis (where the causal relationship between the data and the outcomes are more clearly related) while machine learning is a more brute force approach to prediction (and other analyses). I wanted to put my position out there and see what does or doesn’t resonate with colleagues.
There’s a great Stack Exchange thread on this topic where many folks have chimed in with their take on the two approaches. I’ve done a bit of poking around and there is no shortage of web content on the subject. Here’s a good summary of my take:

This came from a webinar that Blue Canary recently delivered to a university where we explained the process we go through to turn student data into valuable information. As you can see from the slide, while there are functional differences in the two approaches, they both get the job done in the end. Let’s call that the non-purist take on regression vs. machine learning. The differences between the two are not significant enough to rule one or the other out as a practical way to extract value from your data.
In my research, I came across this blog post from Drew Conway called The Data Science Venn Diagram. The post talks about the components of data science including statistical knowledge, software engineering skills, and domain expertise. I tend to associate the statistics knowledge with regression and the ‘hacking skills’ with machine learning. The actual venn diagram is interesting:
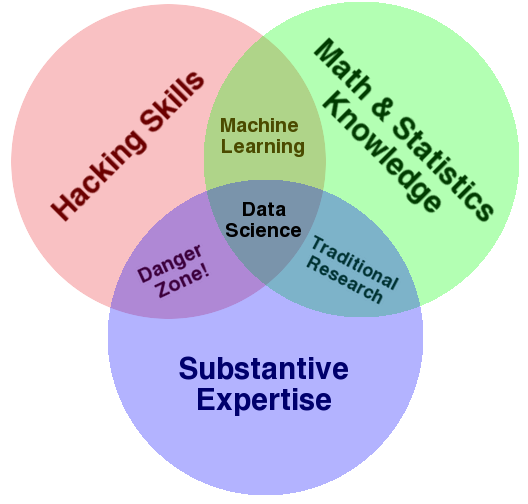
Where I’d disagree is in the Machine Learning sector. The diagram implies that statistics knowledge combined with software skills (but absent of domain expertise) is machine learning. I’d actually label this sector the Danger Zone, just like the domain knowledgeable hacker who has no stats background. I think substantive domain expertise is the keystone in the equation. Whether you come from the hacker side or the stats side, you need to have some domain expertise for two reasons:
- You need to be able to understand the data and the features extracted from the data
- You need to be able to understand the use case and utility of the results
As we always say, you may have a perfect predictive model, but if nobody acts on the information, your model is useless.
So what are your thoughts? Since I’m not the definitive expert in the field, I’d love to hear from colleagues in the educational analytics space about how they view the fields.